Anthropic hat Marketing-Führungskräften versehentlich gezeigt, wie man KI-Agenten besser führt
Das Claude Code Source-Leak enthüllt, wie KI-Agenten im Produktiveinsatz tatsächlich funktionieren. Was Marketing-Führungskräfte daraus für ihre eigenen KI-Workflows lernen können.
Wie sichtbar ist Ihr Unternehmen in KI-Suche?
Finden Sie es in 60 Sekunden heraus. Unser kostenloser AI Visibility Checker prüft ChatGPT, Perplexity und Google AI Overviews.
Jetzt kostenlos prüfen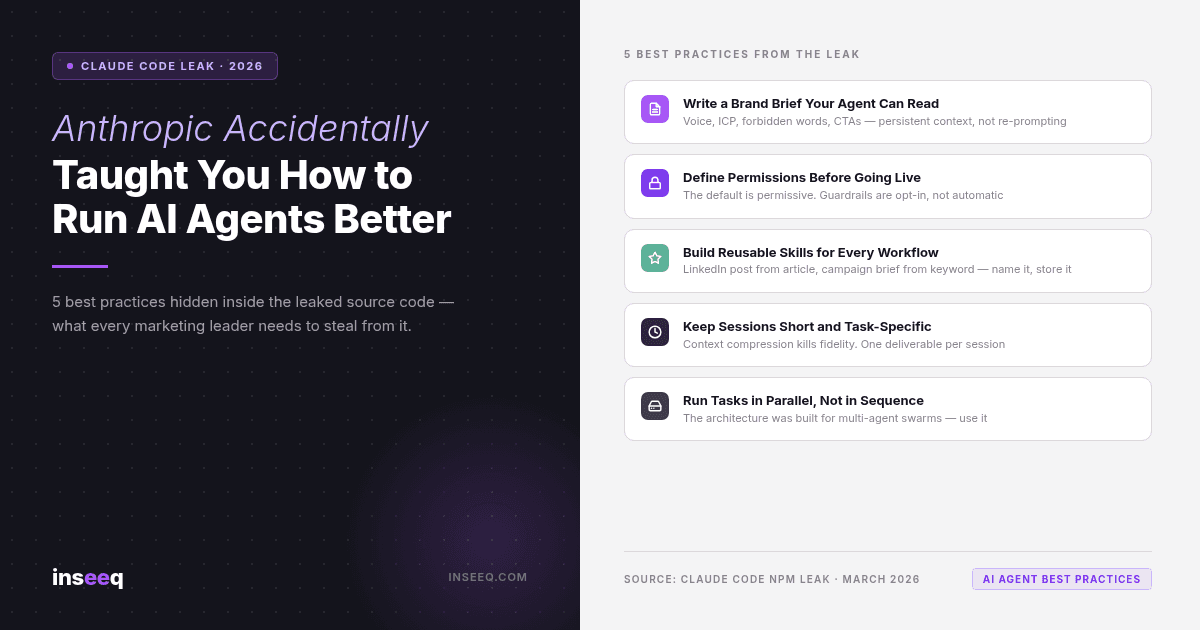
5 AI agent marketing best practices revealed by the Claude Code source leak — checklist graphic by inseeq
Das Leak, über das im Marketing niemand spricht (aber sollte)
Am 31. März 2026 hat Anthropic versehentlich den gesamten Quellcode von Claude Code im öffentlichen npm-Registry veröffentlicht, über eine nicht-obfuskierte Source-Map-Datei. Kein Hack nötig. Jeder, der wusste, wo er suchen musste, konnte 512.000 Zeilen internes TypeScript herunterladen, komplett mit TODO-Kommentaren, Feature-Flags und der vollständigen Architektur eines der fortschrittlichsten KI-Coding-Agenten auf dem Markt.
Entwickler bemerkten es innerhalb von Stunden. Die Geschichte explodierte auf Reddit und X. Sicherheitsforscher archivierten alles, bevor Anthropic reagieren konnte.
Marketing-Führungskräfte haben es größtenteils ignoriert.
Das ist ein Fehler.
Denn in diesem Leak verbirgt sich etwas Nützlicheres als jeder KI-Marketing-Guide, der im vergangenen Jahr veröffentlicht wurde: ein Bauplan dafür, wie produktionsreife KI-Agenten tatsächlich funktionieren. Nicht wie Anbieter sagen, dass sie funktionieren. Nicht die polierte Demo-Version. Die echten Interna.
Und sobald Sie diese Interna verstehen, werden Sie einen KI-Agenten nie wieder auf die gleiche Weise einrichten.
Was der Quellcode tatsächlich über KI-Agenten enthüllt
Die meisten Marketing-Führungskräfte nutzen Claude wie einen sehr schnellen Praktikanten: Prompt eingeben, Output lesen, wiederholen. Der geleakte Quellcode zeigt, dass das darunterliegende System für etwas weitaus Anspruchsvolleres gebaut ist.
Hier ist, was die Architektur tatsächlich enthält, übersetzt vom Ingenieur zum Marketer.
Gedächtnis ist bewusst, nicht automatisch. Die Codebasis enthält ein vollständiges memdir/-Verzeichnis und einen extractMemories-Service, der kontinuierlich Fakten aus Konversationen zieht und für zukünftige Sitzungen speichert. Das ist nicht passiv. Der Agent trifft Ermessensentscheidungen darüber, was er sich merken soll. Wenn Sie Ihrem KI-Agenten nie explizit gesagt haben, was bei Ihrer Marke wichtig ist, hat er diese Entscheidungen für Sie getroffen. Jede Sitzung.
Berechtigungen sind die unsichtbaren Leitplanken. Es gibt eine vollständige Berechtigungsebene, die jeden Tool-Aufruf regelt, den der Agent machen kann. Standardmäßig ist Claude Code permissiv. Er tut, was Sie verlangen, es sei denn, Sie haben Einschränkungen definiert. Für Marketing-Teams mit Agenten, die an Live-Systeme angeschlossen sind (CRMs, E-Mail-Plattformen, Social-Scheduler), ist das relevant. Der Quellcode macht deutlich, dass Leitplanken Opt-in sind, nicht Standard.
Kontextkompression ist real und kostet Genauigkeit. Das compact/-Modul komprimiert automatisch lange Konversationen, wenn das Kontextfenster voll wird. Deshalb werden KI-Outputs im Verlauf einer Sitzung tendenziell fader und generischer. Das System fasst sein eigenes Gedächtnis zusammen, um in die Grenzen zu passen, und Zusammenfassung verliert immer Nuancen. Der Agent, der am Anfang einer Sitzung Ihren markenperfekten Einleitungsabsatz geschrieben hat, arbeitet am Ende mit weniger Informationen.
Skills sind benannte, wiederverwendbare Workflows. Das skills/-Verzeichnis im Quellcode zeigt, dass Claude Code wiederholbare Aufgaben als erstklassige Objekte behandelt. Sie definieren einen Workflow einmal, benennen ihn und rufen ihn auf, ohne erneut prompten zu müssen. Wenn Sie derzeit dieselben Anweisungen in jede neue Sitzung kopieren, machen Sie von Hand, was die zugrundeliegende Architektur automatisieren sollte.
Multi-Agent-Koordination ist das vorgesehene Modell. Das coordinator/-Modul und das TeamCreateTool enthüllen ein System, das für parallele Agent-Schwärme gebaut ist, nicht für lineare Konversation. Ein Agent kann recherchieren, während ein anderer entwirft und ein dritter überprüft. Sequentielle Nutzung ist der langsame Weg. Die Architektur wurde für Parallelität entworfen.
Fünf Best Practices direkt aus dem Leak
Das Leak enthüllt nicht nur, wie das System funktioniert. Es zeigt, wie man es besser nutzt. Hier sind fünf Praktiken, die direkt aus der Quellcode-Architektur abgeleitet sind.
1. Schreiben Sie ein Brand-Briefing, das Ihr Agent tatsächlich lesen kann.
Der geleakte Code referenziert durchgehend CLAUDE.md, eine spezielle Datei, die Claude Code am Anfang jeder Sitzung lädt, um den Betriebskontext herzustellen. Stellen Sie es sich wie ein Onboarding-Dokument für einen neuen Mitarbeiter vor, der zwischen den Schichten alles vergisst.
Ihr CLAUDE.md-Äquivalent sollte enthalten: Ihre Markenstimme (mit Beispielen für guten und schlechten Ton), Ihre Zielgruppe und deren Schmerzpunkte, Ihre freigegebenen CTAs und wie man sie verwendet, Sprache, die der Agent nie verwenden darf, und alle Compliance-Einschränkungen. Das ist nicht optional. Ohne es rät der Agent jede einzelne Sitzung Ihre Präferenzen von Grund auf.
2. Definieren Sie Berechtigungen, bevor Sie etwas live verbinden.
Wenn Ihr KI-Agent Zugang zu Ihrem CRM, Ihrer E-Mail-Plattform oder Ihrem Social-Scheduler hat, müssen Sie genau wissen, was er tun darf. Die geleakte Berechtigungsarchitektur macht deutlich, dass "verbunden" und "eingeschränkt" zwei verschiedene Dinge sind. Bevor Sie Ihre erste automatisierte Kampagne starten, kartieren Sie jedes System, das der Agent berühren kann, und definieren Sie, welche Aktionen menschliche Genehmigung erfordern.
3. Bauen Sie Skills für Ihre wiederholbaren Workflows.
Wenn Sie aus jedem Artikel einen LinkedIn-Post schreiben, ist das ein Skill. Wenn Sie ein Kampagnen-Briefing aus einem Keyword und einer ICP generieren, ist das ein Skill. Wenn Sie einen wöchentlichen E-Mail-Digest aus Ihrem Content-Kalender erstellen, ist das ein Skill. Benennen Sie sie, dokumentieren Sie sie und speichern Sie sie dort, wo der Agent sie laden kann, ohne dass Sie den Prozess neu erklären. So erhalten Sie konsistenten Output statt Output, der variiert, je nachdem, wie Sie sich beim Prompten fühlen.
4. Halten Sie Sitzungen kurz und aufgabenspezifisch.
Kontextkompression ist kein Bug. Sie ist eine architektonische Notwendigkeit. Aber sie bedeutet, dass lange Sitzungen schlechteren Output produzieren als kurze, fokussierte. Die besten KI-Agent-Workflows sehen aus wie eine Reihe kurzer, zielgerichteter Sprints, nicht wie eine Marathon-Sitzung. Eine Sitzung pro Ergebnis. Klarer Start, klares Ende, klarer Output.
5. Führen Sie Aufgaben parallel aus, nicht sequenziell.
Die Multi-Agent-Architektur im Leak ist für Teams von Agenten konzipiert, die gleichzeitig arbeiten. Wenden Sie diese Logik auf Ihr eigenes Setup an. Recherche und Briefing-Erstellung müssen nicht sequenziell passieren. Texterstellung und Bildrecherche müssen nicht sequenziell passieren. Kartieren Sie Ihre Marketing-Workflows und identifizieren Sie, wo Parallelität möglich ist. Sie werden die Produktionszeit erheblich reduzieren, ohne Headcount aufzubauen.
Warum Kontext das neue Creative Briefing ist
Das CLAUDE.md-Konzept aus dem Leak weist auf eine tiefere Wahrheit über die Arbeit mit KI-Agenten im großen Maßstab hin.
Jedes Marketing-Team hat einen Creative-Brief-Prozess. Bevor eine Agentur, ein Freelancer oder ein neuer Mitarbeiter eine Kampagne anfasst, übergeben Sie das Briefing: wer die Zielgruppe ist, wie die Marke klingt, was wir erreichen wollen, was wir schon versucht haben, was tabu ist. Das Briefing ist der Kontext. Ohne ihn fangen alle bei null an, und Sie verbringen die Hälfte des Projekts damit, Fehlausrichtungen zu korrigieren.
KI-Agenten brauchen genau dasselbe. Der Unterschied ist, dass sie nicht zwischen den Zeilen lesen, aus Erfahrung schließen oder klärende Fragen stellen können wie ein Mensch. Sie arbeiten buchstäblich mit dem, was ihnen gegeben wird. Das bedeutet, das Briefing muss vollständiger sein, nicht weniger.
Hier scheitern die meisten KI-Marketing-Setups. Der Kontext fehlt entweder komplett, ist über verschiedene Dokumente verstreut oder wird jede Sitzung von Grund auf neu aufgebaut, weil niemand daran gedacht hat, ihn zu persistieren.
inseeq wurde genau um dieses Problem herum gebaut. Die Plattform behandelt Markenkontext, Zielgruppendefinitionen, Voice-Guidelines und redaktionelle Regeln als erstklassige Objekte, die in einer strukturierten Kontextebene leben, nicht in jemandes Google Drive oder per Copy-Paste in jeden Prompt. Wenn ein inseeq-Agent einen Artikel schreibt, einen Social-Media-Post generiert oder einen Content-Kalender plant, lädt er diesen Kontext automatisch aus einem zentralisierten, versionierten Speicher.
Das Ergebnis ist, was die Architektur des Claude Code Leaks produzieren sollte: konsistenter, markenkonformer Output über Sitzungen, Agenten und Zeit hinweg. Kein erneutes Briefing. Kein Abdriften. Keine Outputs, die sich lesen, als kämen sie von einem anderen Team.
Das ist kein Produktpitch. Es ist die logische Schlussfolgerung dessen, was das Leak selbst enthüllt: Die Kontextebene ist das Wichtigste in einem KI-Agent-Setup, und fast niemand verwaltet sie bewusst.
Was passiert, wenn Sie Kontext nicht richtig einrichten
Die Konsequenzen, das Kontext-Setup zu überspringen, sind vorhersehbar, und sie verstärken sich über die Zeit.
Off-Brand-Copy verstärkt sich schnell. Ein Agent ohne Brand-Briefing wird Inhalte produzieren, die technisch korrekt und tonal falsch sind. Bei niedrigem Volumen ist das eine kleine Unannehmlichkeit. Bei der Veröffentlichungskadenz, die die meisten KI-gestützten Teams anvisieren (3-5 Beiträge pro Woche), wird es innerhalb eines Monats zu einer Markenkonsistenz-Krise.
Session-Drift ist unsichtbar, bis es zu spät ist. Jede Sitzung ohne persistenten Kontext startet frisch. Der Agent erinnert sich nicht, dass Sie Corporate-Buzzwords hassen, dass Ihre ICP ein technischer Gründer ist und kein Enterprise-CMO, oder dass Sie nie Em-Dashes verwenden. Sie werden es am Output bemerken. Dann haben Sie bereits Zeit für Revisionen aufgewendet, die ein gutes Kontext-Setup verhindert hätte.
Halluzinationsrisiko skaliert mit Komplexität. Wenn ein Agent keinen zuverlässigen Kontext über Ihre Produkte, Preise und bisherigen Ergebnisse hat, füllt er die Lücke mit plausibel klingendem Content. Je autonomer Ihr Setup, desto weiter kann dieser fabrizierte Content reisen, bevor ein Mensch ihn sieht.
Parallele Agenten ohne geteilten Kontext produzieren inkohärente Outputs. Die Multi-Agent-Architektur aus dem Leak ist nur nützlich, wenn alle Agenten aus derselben Kontextquelle schöpfen. Wenn Ihr Recherche-Agent und Ihr Texterstellungs-Agent unterschiedliche Versionen Ihrer Markenstimme haben, wird der Output sich lesen, als wäre er von zwei verschiedenen Personen geschrieben worden. Denn genau das ist der Fall.
Die Unternehmen, die echte Ergebnisse aus KI-gestütztem Marketing erzielen, nicht Demo-Ergebnisse, sondern nachhaltigen wöchentlichen Output, der tatsächlich konvertiert, haben zuerst das Kontextproblem gelöst. Das Claude Code Leak hat nur zufällig in 512.000 Zeilen TypeScript gezeigt, warum genau das stimmt.
Häufig gestellte Fragen
Was ist das Claude Code Source-Leak? Am 31. März 2026 hat Anthropic versehentlich eine nicht-obfuskierte Source-Map in ihr Claude Code npm-Paket aufgenommen. Dadurch wurde der vollständige TypeScript-Quellcode von Claude Code über Anthropics R2-Storage-Bucket ohne Authentifizierung öffentlich zugänglich. Das Repository auf github.com/instructkr/claude-code spiegelt den exponierten Snapshot für Sicherheitsforschungszwecke.
Was ist eine CLAUDE.md-Datei und sollten Marketing-Teams eine verwenden? CLAUDE.md ist eine Konfigurationsdatei, die Claude Code am Anfang jeder Sitzung lädt, um den Betriebskontext herzustellen, ähnlich einem Onboarding-Dokument für den Agenten. Marketing-Teams, die einen beliebigen KI-Agenten nutzen, sollten ein äquivalentes Dokument pflegen, das Markenstimme, Zielgruppendefinitionen, freigegebenes Messaging und verbotene Sprache abdeckt. Ohne es leitet der Agent den Kontext jede Sitzung von Grund auf ab.
Wurden durch das Leak Daten von Unternehmen exponiert, die Claude nutzen? Nein. Das Leak exponierte Quellcode darüber, wie Claude Code funktioniert, nicht Kundendaten oder Konversationsprotokolle. Die Sicherheitsbedenken bestehen darin, dass Wettbewerber und Forscher nun Anthropics architektonische Entscheidungen und kommende Features (sichtbar über Feature-Flags im Code) reverse-engineeren können.
Wie beeinflusst Kontextkompression den KI-Marketing-Output? Wenn eine Konversationssitzung lang wird, fasst das Kontextkompressionsmodul von Claude frühere Austausche automatisch zusammen, um innerhalb der Token-Limits zu bleiben. Das bedeutet, der Agent verliert progressiv Nuancen vom Anfang der Sitzung. Praktisch: Kürzere, fokussierte Sitzungen produzieren konsistenteren Output als Marathon-Sitzungen.
Was ist der Unterschied zwischen einem KI-Agenten und mehreren parallel? Ein einzelner Agent arbeitet sequenziell: Er beendet eine Aufgabe, bevor er die nächste beginnt. Multi-Agent-Setups führen Aufgaben gleichzeitig mit einem Koordinator aus, der Arbeit über spezialisierte Agenten verteilt. Für Marketing bedeutet das: Recherche, Texterstellung und Bildrecherche können gleichzeitig stattfinden statt nacheinander, was die Produktionszeit erheblich reduziert.
Ist es sicher, Claude nach diesem Leak für Marketing zu nutzen? Das Leak war ein operativer Sicherheitsfehler, kein Modell-Kompromiss. Claudes zugrundeliegende Fähigkeiten und Sicherheitssysteme waren nicht betroffen. Die wichtigste praktische Überlegung für Marketing-Teams ist die Anbieter-Zuverlässigkeit: Anthropic hatte innerhalb einer Woche zwei größere Expositions-Vorfälle (das Claude Code Leak und eine CMS-Fehlkonfiguration, die interne Modelldokumente exponierte). Teams sollten prüfen, welche Daten durch Claude-Integrationen fließen, und sicherstellen, dass ihre Anbieterverträge Klauseln zur Verletzungsmeldung enthalten.
Wie kann inseeq beim KI-Agent-Kontextmanagement helfen? inseeq verwaltet die Kontextebene, die KI-Agenten brauchen, um konsistenten, markenkonformen Output zu produzieren. Markenstimme, Zielgruppenprofile, redaktionelle Regeln und Content-Strategie werden in einem strukturierten, versionierten System gespeichert, das Agenten automatisch am Anfang jeder Sitzung laden. Das eliminiert das Neu-Briefing-Problem und verhindert Marken-Drift über Sitzungen und Agenten hinweg.
Richten Sie Ihr KI-Agent-Setup von Anfang an richtig ein
Das Claude Code Leak hat Marketing-Führungskräften ein seltenes Geschenk gemacht: einen Blick ins Innere, wie produktionsreife KI-Agenten tatsächlich aufgebaut sind. Die Teams, die aufmerksam sind, werden KI-Marketing-Setups bauen, die konsistente Ergebnisse produzieren. Die Teams, die es nicht tun, werden weiterhin Output erhalten, der abdriftet, variiert und ständige menschliche Korrektur erfordert.
Kontext ist das Fundament. Alles andere baut darauf auf.
Wenn Sie sehen möchten, wie inseeq die Kontextebene für KI-gestütztes Marketing strukturiert, und wie das in der Praxis für B2B-Teams aussieht, buchen Sie ein kostenloses Growth Audit unter inseeq.com/de/contact. Kein Pitch-Deck. Wir schauen uns Ihr aktuelles Setup an, identifizieren die Lücken und zeigen Ihnen konkret, was sich ändern muss.

Hans-Peter Frank
Co-founder
Wie sichtbar ist Ihr Unternehmen in KI-Suche?
Finden Sie es in 60 Sekunden heraus. Unser kostenloser AI Visibility Checker prüft ChatGPT, Perplexity und Google AI Overviews.
Jetzt kostenlos prüfen